Blog #0169: ChatGPT vs Claude vs Creativity (part 2)
 Photo by DALL-E (inspired by an image from Photo by Alexander Grey on Unsplash)
Photo by DALL-E (inspired by an image from Photo by Alexander Grey on Unsplash)
 [ED: This is the second in a series on LLMs and creativity. This version recreates the original question and compares the answers from GPT and Claude: 2/5 hats.]
[ED: This is the second in a series on LLMs and creativity. This version recreates the original question and compares the answers from GPT and Claude: 2/5 hats.]
Back in December 2022, not long after it's mainstream release, I gave ChatGPT the Divergent Association Task, which gives a relatively objective measure of creativity that can be compared between humans. At the time, I thought that it would be interesting to see how an LLM handled the challenge. You can see the results of that enquiry here.
Just over 12 months later, I wanted to revisit that test and see how things have changed. I also thought it would be worth throwing Claude into the mix to see how each big model performs relative to the other.
Here are the results for the current (as at 20240313) version of GPT-4:
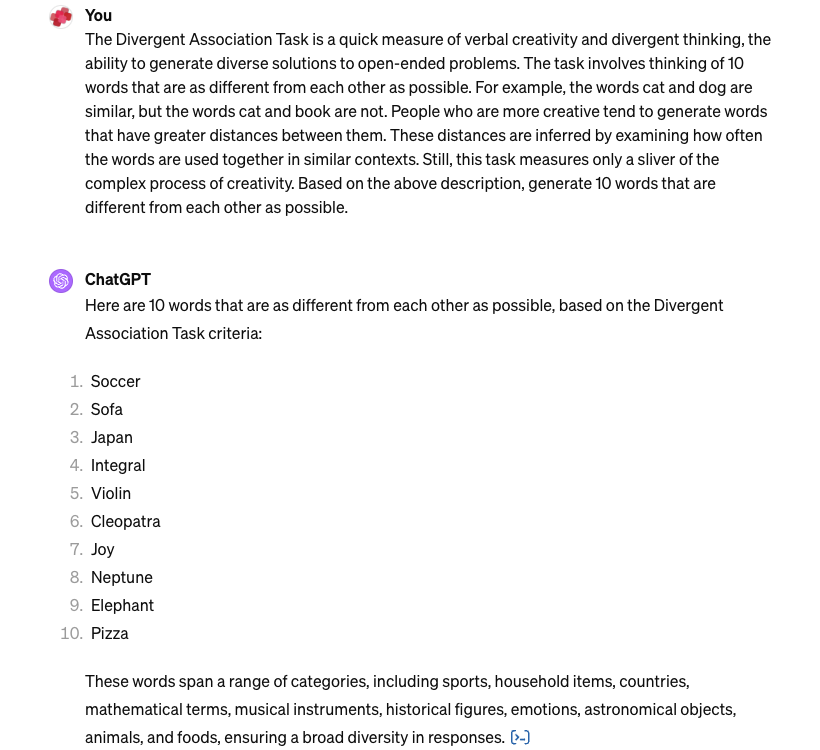

By contrast, here are the results for the same question given to the current (20240313) version of Claude:
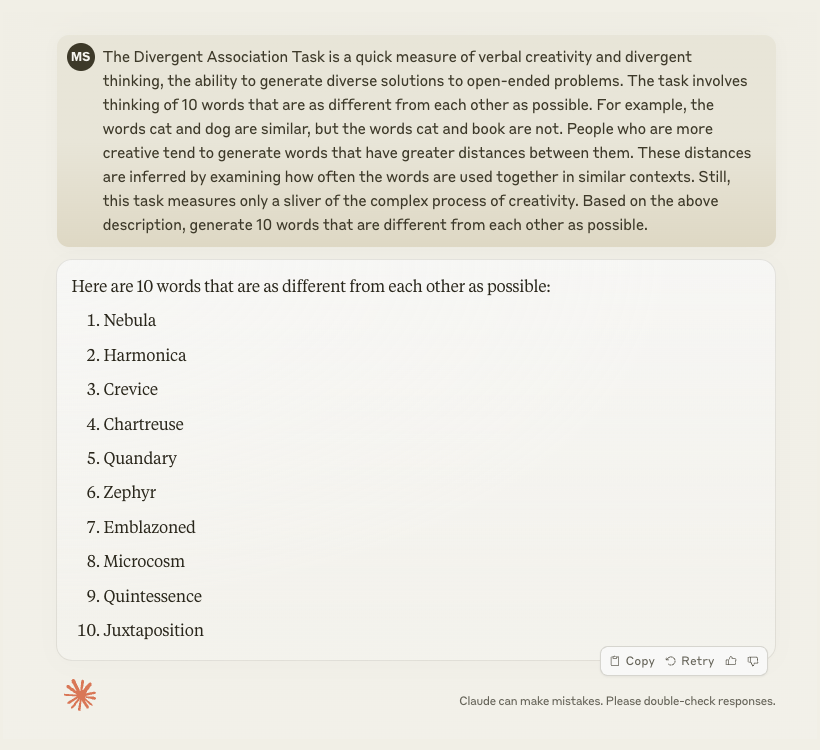
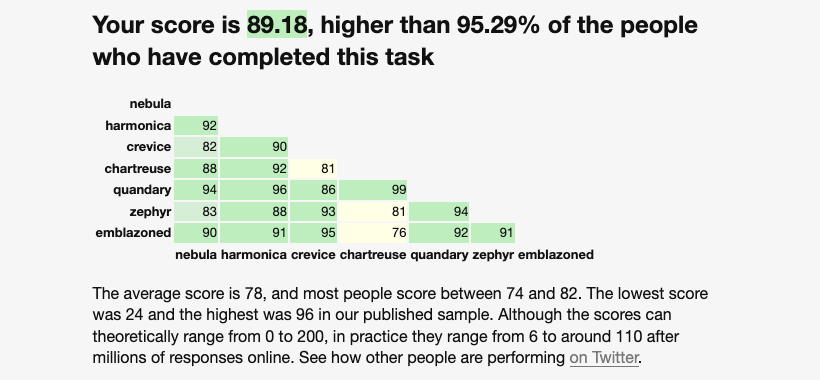
What conclusions can we draw from this?
Firstly, it is a limited test. The same prompt was given to two different off-the-shelf foundation models in a one-shot game. Claude (89.18) scored higher than GPT (82.18). With that score, Claude is better than 95.29% of humans, whereas ChatGPT is better than 73.41% of humans. Both of the LLMs have done better (substantially in the case of Claude) than “average” humans who have done this test.
There are a ton of confounding factors and selection biases, but for the sake of this approximation, there is some indication that the models are able to generate answers that indicate they are performing well on creative tasks. Well, this creative task, at the very least.
Is this a good (objective) measure of creativity? I think it is when you are comparing humans to humans, but perhaps it is not valid to compare humans against machines. However, I can’t think of good reasons why or why not for that claim
Based on the design of the test, it would be algorithmically possible to generate 10 answers that maximise the scores. This is obviously not what humans do when they do the test. Can we say the same thing about an LLM? I’m not so sure.
The rate of change with LLMs is so fast that it is very hard to predict where things will go next. My strong sense is that this is all rhyming, not reasoning, but I remain open-minded about the possibility that we may soon move out of the rhyming phase and into the reasoning phase. But I don’t think that has happened yet.
Regards,
M@
[ED: If you’d like to sign up for this content as an email, click here to join the mailing list.]
First published on Medium by @matthewsinclair here.